Currently Empty: ₹0.00
Spring Batch
Home
Overview
Introduction
ETL Process
Components
Basic Architecture
Detailed Architecture
Job Details
Step Details
JobRepository
ItemReader:
Job Configuration
Configuring JobRepository
JobLauncher Configuration
Running a Job
Guidelines
Strategy Insights
Sample Project & Code
Resources
Spring Batch
Spring Batch is a versatile and lightweight framework designed for the development of Batch Applications within Enterprise environments. This comprehensive tutorial elucidates the foundational concepts of Spring Batch and demonstrates its practical application.
Target Audience:
This tutorial caters to professionals tasked with handling substantial volumes of records, engaging in repetitive actions such as transaction management, job processing statistics, and resource management. If you find yourself dealing with high-volume batch jobs, Spring Batch proves to be an exceptionally efficient framework for your needs.
Prerequisites:
To make the most of this tutorial, it is essential to have a prior understanding of the features and functions of the Spring Framework. If you are unfamiliar with Spring Framework, we recommend starting your journey there to ensure a seamless learning experience.
Overview
A lightweight, comprehensive batch framework designed to enable the development of robust batch applications vital for the daily operations of enterprise systems. Spring Batch provides reusable functions that are essential in processing large volumes of records, including logging/tracing, transaction management, job processing statistics, job restart, skip, and resource management. It also provides more advanced technical services and features that will enable extremely high-volume and high-performance batch jobs through optimization and partitioning techniques. Simple as well as complex, high-volume batch jobs can leverage the framework in a highly scalable manner to process significant volumes of information
Features
– Transaction management
– Chunk based processing
– Declarative I/O
-Start/Stop/Restart
-Retry/Skip
-Web based administration interface
Introduction
Spring Batch simplifies bulk processing for enterprise applications, tackling essential operations like automated large-scale data processing and repetitive rule applications. Whether handling time-based events or integrating data from various sources, Spring Batch streamlines the development of robust batch applications crucial for daily enterprise functions. Built upon the familiar Spring Framework, Spring Batch maintains a lightweight and comprehensive approach, ensuring ease of use and productivity. It doesn’t replace schedulers but seamlessly integrates with them. Spring Batch offers reusable functions, including logging, transaction management, statistics, restart, skip, and resource management. Additionally, it provides advanced services for optimized and partitioned high-volume batch jobs, accommodating both simple and complex scenarios, from file-to-database transfers to intricate data transformations.
Usage Scenarios
A typical batch program generally:
–Reads a large number of records from a database, file, or queue
–Processes the data in some fashion
–Writes back data in a modified form.
Spring Batch automates this basic batch iteration, providing the capability to process similar transactions as a set, typically in an offline environment without any user interaction. Batch jobs are part of most IT projects, and Spring Batch is the only open-source framework that provides a robust, enterprise-scale solution.
Business Scenarios
Spring Batch supports the following business scenarios
–Commit batch process periodically
–Concurrent batch processing: parallel processing of a job.
-Staged, enterprise message-driven processing
-Massively parallel batch processing
-Manual or scheduled restart after failure
-Sequential processing of dependent steps (with extensions to workflow-driven batches)
–Partial processing: skip records (for example, on rollback).
-Whole-batch transaction, for cases with a small batch size or existing stored procedures or scripts.
Introduction to ETL Process
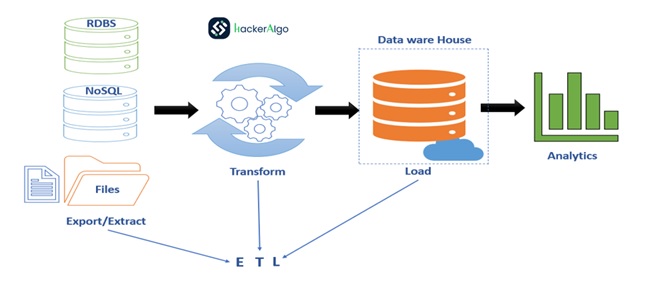
–ETL stands for “extract, transform, and load
-ETL process collects and refines different types of data, then delivers the data to a data warehouse such as Redshift, Azure, or BigQuery.
-ETL Tools: Talend, Informatica, Oracle Data Integrator
Spring Batch Components
1. Job Repository:
Description: Represents the persistence of batch meta-data entities in the database. It acts as a repository containing information about batch jobs, such as the timestamp of the last run.
Functionality: Stores and manages metadata related to job executions, steps, and other batch-related information.
2. Job Launcher:
Description: An interface used to launch or run jobs based on a predefined schedule or on-demand. It takes the job’s name and additional parameters during job execution.
Functionality: Initiates the execution of a specified job, triggering the associated steps in the job.
3. Job:
Description: The primary module that encapsulates the entire business logic to be executed. It may consist of one or more steps.
Functionality: Defines and organizes the high-level processing logic for a specific task or set of tasks.
4. Step:
Description: Represents a distinct phase or unit of work within a job. Complex jobs can be divided into multiple steps or chunks, executed sequentially.
Functionality: Defines a specific sequence of actions, including reading, processing, and writing data.
5. ItemReader:
Description: An interface used for bulk-reading data from a source, such as a file or database. For example, reading several lines of data from an Excel file at the beginning of a job.
Functionality: Reads data in chunks or batches, providing a stream of input data to be processed.
6. ItemProcessor:
Description: Performs data processing based on the business logic defined by the developer. It operates on the data read by the ItemReader.
Functionality: Applies custom processing to each item of data, transforming it or performing any necessary computations.
7. ItemWriter:
Description: An interface responsible for writing bulk data, either to a database, file, or any other storage medium. It receives the processed data from the ItemProcessor.
Functionality: Persists the processed data in the desired format or location, completing the batch processing cycle.
A chunk is a child element of the tasklet. It is used to perform read, write, and processing operations.
Basic Architecture:
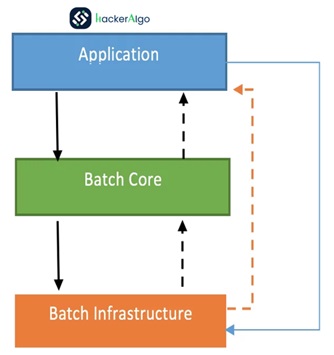
Spring Batch is designed with extensibility and a diverse group of end users in mind. The following image shows the layered architecture that supports the extensibility and ease of use for end-user developers. This layered architecture promotes modular design, allowing developers to focus on their specific application logic within the Application layer while leveraging the shared services and runtime classes provided by the Core and Infrastructure layers. The cohesive integration ensures a seamless development experience and supports the extensibility of the Spring Batch framework.
Layered Architecture:
Spring Batch is structured with a layered architecture that emphasizes extensibility and accommodates diverse end-users. The architecture comprises three major high-level components: Application, Core, and Infrastructure.
Application Layer:
Description: This layer encapsulates all batch jobs and custom code developed by end-user developers using Spring Batch.
Components: Batch Jobs& Custom Code.
Core Layer:
Description: The core layer houses the fundamental runtime classes essential for launching and controlling batch jobs.
Components: JobLauncher, Job&Step.
Infrastructure Layer:
Description: The shared infrastructure layer serves as the common foundation supporting both the application and core layers.
Components: Common Readers and Writers. Services (e.g., RetryTemplate)
Functionality:
Common services and utilities, including readers and writers (e.g., ItemReader and ItemWriter), are utilized by application developers.
The core framework also leverages these services, demonstrating a cohesive integration across the architecture. Services like RetryTemplate are part of the infrastructure and can be employed by both application developers and the core framework.
Spring Batch Process – HLD
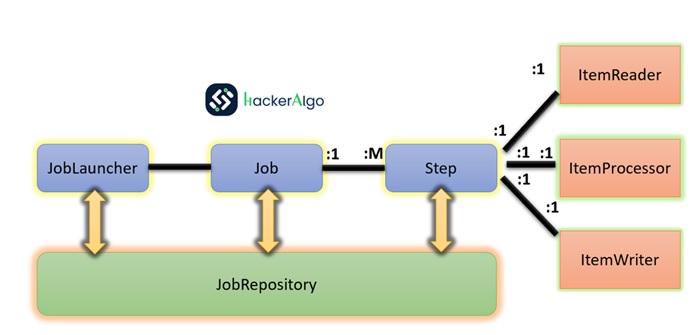
Jobs are launched by the Job Repository via JobLauncher. Each job comprises sequential steps: data is read using Item Reader, processed with Item Processor, and then written to the target system using Item Writer. This structured workflow ensures effective batch processing.
Spring Batch Process – MLD
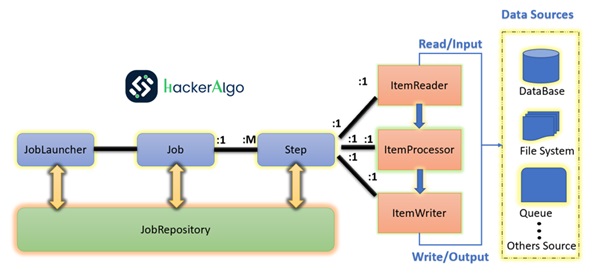
In the workflow shown, the data is read from database using reader which is part of the Spring Batch.
Then the data is passed to processor for processing the data based on the business requirement.
The processed data which is now modified data is passed to the writer, which writes the data back into the database.
The source of data can be Database, file, queue etc.
Spring Batch Process – LLD
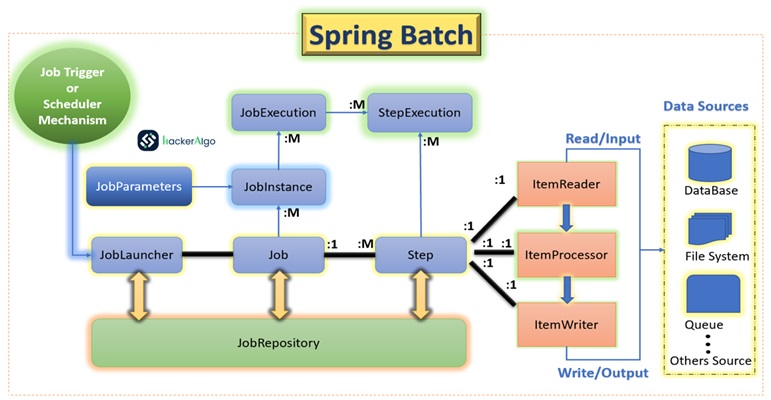
The Job Repository, facilitated by the JobLauncher, oversees the execution of jobs. Each job instance is associated with a JobExecution capturing execution details. Customizable job parameters influence runtime behavior. The workflow includes sequential steps utilizing the Item Reader for input, Item Processor for business logic, and Item Writer for output. This structured approach ensures organized, efficient, and parameterizable batch processing
Job Repository:
Responsibility: Manages metadata for batch jobs.
Functionality: Stores information about job execution status, execution history, and other relevant details.
Connection: Directly interacts with Job Launcher for job initiation.
Job Launcher:
Responsibility: Initiates and controls the execution of batch jobs.
Functionality: Takes input parameters such as job name and initiates the corresponding job.
Connection: Invokes JobRepository to store job metadata.
JobParameters:
Responsibility: Input values provided when launching a job.
Functionality: Customizes job behavior based on dynamic input.
Connection: Passed to the JobLauncher, influencing the job’s runtime behavior.
Job:
Responsibility: Represents a unit of work with specific business logic.
Functionality: Comprises one or more steps executed in sequence.
Connection: Orchestrates the execution flow and interacts with JobLauncher.
JobInstance:
Responsibility: Represents a logical instance of a job.
Functionality: Differentiates between multiple executions of the same job.
Connection: Managed by the Job Repository, ensuring unique job instances.
JobExecution:
Responsibility: Captures the execution details of a specific job instance.
Functionality: Records information like start time, end time, and exit status.
Connection: Created and updated by the JobLauncher during job execution.
Steps:
Responsibility: Breaks down a job into smaller, manageable units.
Functionality: Executes a specific task, often involving ItemReader, ItemProcessor & ItemWriter.
Connection: Ensures sequential execution of tasks within a job.
Item Reader:
Responsibility: Reads data from a specified source.
Functionality: Fetches data in chunks, facilitating efficient processing.
Connection: Interfaces with Job and passes data to the Item Processor.
Item Processor:
Responsibility: Applies business logic to the input data.
Functionality: Processes each item received from the Item Reader.
Connection: Typically follows the Item Reader and precedes the Item Writer.
Step Execution:
Responsibility: Represents the execution of an individual step within a job.
Functionality: Manages the execution status, transitions, and statistics for a specific step.
Connection: Integral to the sequential execution of steps within a job.
Item Writer:
Responsibility: Writes processed data to a target system.
Functionality: Handles bulk writing of data to improve performance.
Connection: Receives processed data from the Item Processor.
Spring Batch JOB in Details
In the realm of Spring Batch, which caters to batch processing, the fundamental concepts involve “Jobs” and “Steps.” These are orchestrated with developer-supplied processing units known as “ItemReader” and “ItemWriter.” Leveraging Spring patterns, operations, templates, callbacks, and idioms, several advantages emerge:
Clear Separation of Concerns: There’s a notable enhancement in adhering to a clear separation of concerns.
Clear Separation of Concerns: There’s a notable enhancement in adhering to a clear separation of concerns.
Architectural Layers: The architectural layers are well-defined, providing services through interfaces.
Simple Default Implementations: Out-of-the-box, there are simple and default implementations that facilitate quick adoption and ease of use.
Enhanced Extensibility: The framework offers significantly enhanced extensibility, allowing developers to tailor and extend functionalities.
The batch reference architecture, depicted in a simplified diagram, serves as a blueprint rooted in decades of proven implementations across various platforms (COBOL on mainframes, C on Unix, and now Java everywhere). This architecture encompasses key components, providing a foundation for creating batch applications ranging from simple to complex. Spring Batch, as an implementation, encapsulates layers, components, and technical services commonly found in robust and maintainable systems.
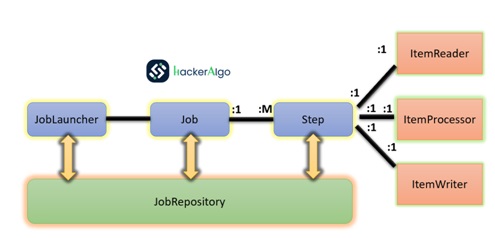
Batch Stereotypes Diagram
The diagram illustrates essential concepts in the domain language of Spring Batch. A “Job” consists of one or more “Steps,” each featuring an “ItemReader,” “ItemProcessor,” and “ItemWriter.” To initiate a job, the “JobLauncher” is employed, and metadata about the ongoing process is stored in the “JobRepository.” This structure caters to the needs of batchprocessing, offering a robust foundation with the flexibility to address both straightforward and intricate processing requirements.
Job:
In Spring Batch, a Job is like a big container that holds an entire batch process. Imagine it as a box that encapsulates a series of related tasks. You set up this job using either an XML configuration file or Java code, which is often called the “job configuration.” However, a Job is just the starting point in a larger structure, illustrated in the Job Hierarchy diagram

The Job contains:
Name of the job: This is just a label to identify the job.
Definition and ordering of Step instances: Steps are individual tasks within the job. They represent the smaller units of work that make up the entire batch. You specify what steps to perform and in what order.
Restartability: You can configure whether the job can be restarted if it fails. This is useful for resuming processing from where it left off.
Here’s a simplified example in Java:
@Configuration
public class BatchConfiguration {
@Bean
public Job footballJob(JobRepository jobRepository) {
return new JobBuilder("footballJob", jobRepository)
.start(playerLoad())
.next(gameLoad())
.next(playerSummarization())
.build();
}
@Bean
public SimpleJobLauncher jobLauncher(JobRepository jobRepository) {
SimpleJobLauncher jobLauncher = new SimpleJobLauncher();
jobLauncher.setJobRepository(jobRepository);
return jobLauncher;
}
// Other beans for steps, readers, writers, etc.JobInstance:
A JobInstance is like a record of a specific run of a batch job. Think of it as a single occurrence of a job, such as the daily “EndOfDay Job.” Even though it’s the same job, each run is tracked separately. For instance, there’s a JobInstance for January 1st, another for January 2nd, and so on.
If a run on January 1st fails initially and is rerun on the next day, it’s still considered part of the January 1st JobInstance. This is typically tied to the data it processes, meaning the January 1st run handles data for January 1st. Each JobInstance can have multiple executions (we’ll talk about JobExecution later), but only one JobInstance, tied to specific JobParameters, can run at any given time.
The JobInstance definition doesn’t affect the data loading process; that’s determined by the ItemReader. For example, in an “EndOfDay” scenario, the data might have a column indicating the effective date. So, the January 1st run would load data from the 1st, and the January 2nd run would load data from the 2nd. The decision on how to load data is often a business choice left to the ItemReader.
Using the same JobInstance helps decide whether to use the “state” from previous executions (like ExecutionContext, discussed later). Starting a new JobInstance means beginning from the start, while using an existing one generally means picking up from where it left off.
JobParameters:
In the context of batch processing, distinguishing between different executions of a job is facilitated by “JobParameters.” When initiating a batch job, a set of parameters encapsulated in a “JobParameters” object is utilized. These parameters serve purposes such as identification or referencing data during the job run.
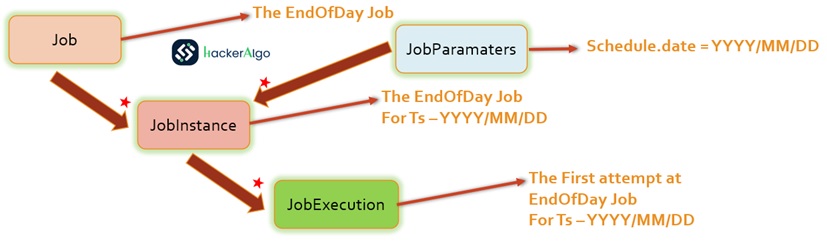
For instance, consider two instances—one for January 1st and another for January 2nd. Although there is essentially one job, there exist two distinct “JobParameter” objects: one initiated with a job parameter of 01-01-2017 and another with a parameter of 01-02-2017. The relationship is conceptualized as follows: JobInstance = Job +identifyingJobParameters. This establishes a contract empowering developers to define a “JobInstance” effectively by controlling the parameters passed in, thereby influencing how job instances are distinguished.
Job Execution:
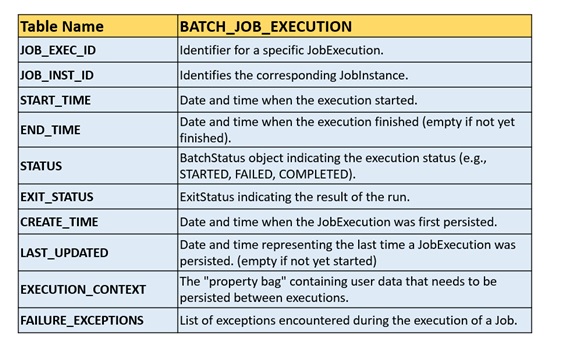
A JobExecution refers to the technical concept of a single attempt to run a Job. An execution may end in failure or success, but the JobInstance corresponding to a given execution is not considered to be complete unless the execution completes successfully. Using the EndOfDay Job described previously as an example, consider a JobInstance for 01-01-2017 that failed the first time it was run. If it is run again with the same identifying job parameters as the first run (01-01-2017), a new JobExecution is created. However, there is still only one JobInstance. A Job defines what a job is and how it is to be executed, and a JobInstance is a purely organizational object to group executions together, primarily to enable correct restart semantics. A JobExecution, however, is the JobExecutionprimary storage mechanism for what actually happened during a run and contains many more properties that must be controlled and persisted, as the following table shows:
Job Execution Properties:

These properties provide essential information for tracking and understanding the status and details of a JobExecution.
These properties are important because they are persisted and can be used to completely determine the status of an execution. For example, if the EndOfDay job for 01-01 is executed at 9:00 PM and fails at 9:30, the following entries are made in the batch metadata table (JOB):
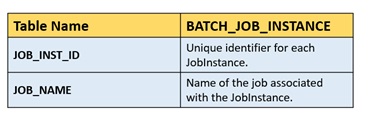
BATCH_JOB_INSTANCE:
BATCH_JOB_EXECUTION_PARAMS
BATCH_JOB_EXECUTION
Below tables store information about job instances, job execution parameters, and the execution details, providing a comprehensive view of the batch processing execution.

Example with Job table details:

Now that the job has failed, assume that it took the entire night for the problem to be determined, so that the “batch window” is now closed. Further assuming that the window starts at 9:00 PM, the job is kicked off again for 01-01, starting where it left off and completing successfully at 9:30. Because it is now the next day, the 01-02 job must be run as well, and it is kicked off just afterwards at 9:31 and completes in its normal one hour time at 10:30. There is no requirement that one JobInstance be kicked off after another, unless there is potential for the two jobs to attempt to access the same data, causing issues with locking at the database level. It is entirely up to the scheduler to determine when a Job should be run. Since they are separate JobInstances, Spring Batch makes no attempt to stop them from being run concurrently. (Attempting to run the same JobInstance while another is already running results in a JobExecutionAlreadyRunningException being thrown). There should now be an extra entry in both the JobInstance and JobParameters tables and two extra entries in the JobExecution table
Sample code for Job Instance and Job Parameters
JobParameters jobParameters = new JobParametersBuilder()
.addString(“date”, “01-01-2023”)
.toJobParameters();
JobExecution jobExecution = jobLauncher.run(footballJob, jobParameters);
Step:
A Step is a building block of a batch job, representing an independent, sequential phase of processing. Every Job is composed of one or more steps. The contents of a Step are determined by the developer, allowing for simplicity or complexity based on the job’s requirements. For instance, a Step can range from loading data into a database with minimal code to implementing complex business rules. Each Step has its own StepExecution, which corresponds to a unique JobExecution.

Step Configuration Sample Java Code:
@Bean
public Step playerLoad() {
return stepBuilderFactory.get("playerLoad")
.<PlayerInput, PlayerOutput>chunk(10)
.reader(playerItemReader())
.processor(playerItemProcessor())
.writer(playerItemWriter())
.build(();)();
}
StepExecution:
A StepExecution represents a single attempt to execute a Step. A new StepExecution is created each time a Step is run, similar to JobExecution. However, if a step fails to execute because the step before it fails, no execution is persisted for it. A StepExecution is created only when its Step is actually started.
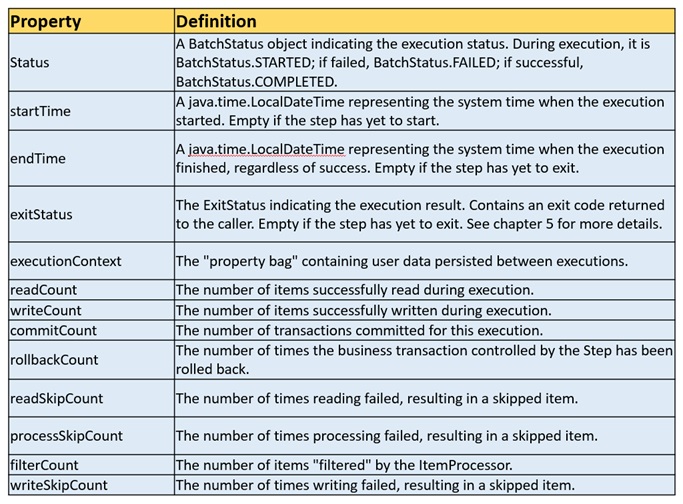
Step executions are represented by objects of the StepExecution class. Each execution contains a reference to its corresponding step and JobExecution and transaction-related data, such as commit and rollback counts and start and end times. Additionally, each step execution contains an ExecutionContext, which contains any data a developer needs to have persisted across batch runs, such as statistics or state information needed to restart.
The following table lists the properties for StepExecution.
Step Execution Context:
An ExecutionContext represents a collection of key/value pairs that are persisted and controlled by the framework to give developers a place to store persistent state that is scoped to a StepExecution object or a JobExecution object. (For those familiar with Quartz, it is very similar to JobDataMap.) The best usage example is to facilitate restart. Using flat file input as an example, while processing individual lines, the framework periodically persists the ExecutionContext at commit points. Doing so lets the ItemReader store its state in case a fatal error occurs during the run or even if the power goes out. All that is needed is to put the current number of lines read into the context, as the following example shows, and the framework does the rest.
executionContext.putLong(getKey(LINES_READ_COUNT), reader.getPosition());
There are two tables for Step
BATCH_STEP_EXECUTION
BATCH_STEP_EXECUTION_CONTEXT
Using the EndOfDay example from the Job stereotypes section as an example, assume there is one step, loadData, that loads a file into the database. After the first failed run, the metadata tables would look like the following example:
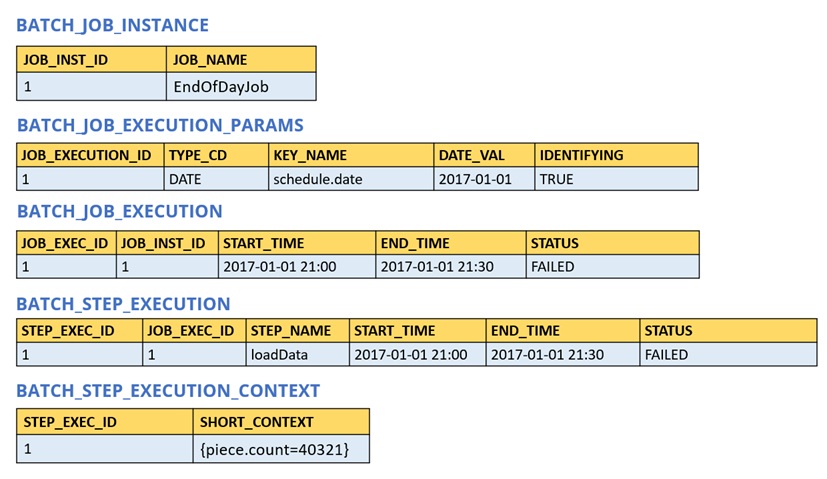
In the preceding case, the Step ran for 30 minutes and processed 40,321 “pieces”, which would represent lines in a file in this scenario. This value is updated just before each commit by the framework and can contain multiple rows corresponding to entries within the ExecutionContext. Being notified before a commit requires one of the various StepListener implementations (or an ItemStream), which are discussed in more detail later in this guide. As with the previous example, it is assumed that the Job is restarted the next day. When it is restarted, the values from the ExecutionContext of the last run are reconstituted from the database. When the ItemReader is opened, it can check to see if it has any stored state in the context and initialize itself from there, as the following example shows:
if (executionContext.containsKey(getKey(LINES_READ_COUNT))) {
log.debug("Initializing for restart. Restart data is: " + executionContext);
long lineCount = executionContext.getLong(getKey(LINES_READ_COUNT));
LineReader reader = getReader();
Object record = "";
while (reader.getPosition() < lineCount && record != null) {
record = readLine();
}
}
In this case, after the preceding code runs, the current line is 40,322, letting the Step start again from where it left off. You can also use the ExecutionContext for statistics that need to be persisted about the run itself. For example, if a flat file contains orders for processing that exist across multiple lines, it may be necessary to store how many orders have been processed (which is much different from the number of lines read), so that an email can be sent at the end of the Step with the total number of orders processed in the body. The framework handles storing this for the developer, to correctly scope it with an individual JobInstance. It can be very difficult to know whether an existing ExecutionContext should be used or not. For example, using the EndOfDay example from above, when the 01-01 run starts again for the second time, the framework recognizes that it is the same JobInstance and on an individual Step basis, pulls the ExecutionContext out of the database, and hands it (as part of the StepExecution) to the Step itself. Conversely, for the 01-02 run, the framework recognizes that it is a different instance, so an empty context must be handed to the Step. There are many of these types of determinations that the framework makes for the developer, to ensure the state is given to them at the correct time. It is also important to note that exactly one ExecutionContext exists per StepExecution at any given time. Clients of the ExecutionContext should be careful, because this creates a shared keyspace. As a result, care should be taken when putting values in to ensure no data is overwritten. However, the Step stores absolutely no data in the context, so there is no way to adversely affect the framework.
Note that there is at least one ExecutionContext per JobExecution and one for every StepExecution. For example, consider the following code snippet:
ExecutionContext ecStep = stepExecution.getExecutionContext();
ExecutionContext ecJob = jobExecution.getExecutionContext();
//ecStep does not equal ecJob
As noted in the comment, ecStep does not equal ecJob. They are two different ExecutionContexts. The one scoped to the Step is saved at every commit point in the Step, whereas the one scoped to the Job is saved in between every Step execution.
JobRepository:
JobRepository is the persistence mechanism for all of the stereotypes mentioned earlier. It provides CRUD operations for JobLauncher, Job, and Step implementations. When a Job is first launched, a JobExecution is obtained from the repository. Also, during the course of execution, StepExecution and JobExecution implementations are persisted by passing them to the repository.
When using Java configuration, the @EnableBatchProcessing annotation provides a JobRepository as one of the components that is automatically configured.
JobRepository Configuration:
import org.springframework.batch.core.repository.support.JobRepositoryFactoryBean;
import org.springframework.transaction.PlatformTransactionManager;
Need to add code mirror
JobLauncher:
JobLauncher represents a simple interface for launching a Job with a given set of JobParameters, as the following example shows:
public interface JobLauncher {
public JobExecution run(Job job, JobParameters jobParameters)
throws JobExecutionAlreadyRunningException, JobRestartException,
JobInstanceAlreadyCompleteException, JobParametersInvalidException;
}
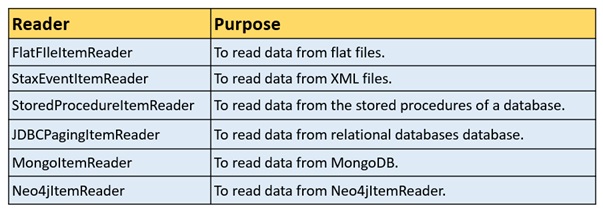
ItemReader:
ItemReader is an abstraction that represents the retrieval of input for a Step, one item at a time. When the ItemReader has exhausted the items it can provide, it indicates this by returning null.

Following are some of the predefined ItemReader classes provided by Spring Batch to read from various sources.
ItemWriter
ItemWriter is an abstraction that represents the output of a Step, one batch or chunk of items at a time. Generally, an ItemWriter has no knowledge of the input it should receive next and knows only the item that was passed in its current invocation.

Following are some of the predefined ItemWriter classes provided by Spring Batch to read from various sources.
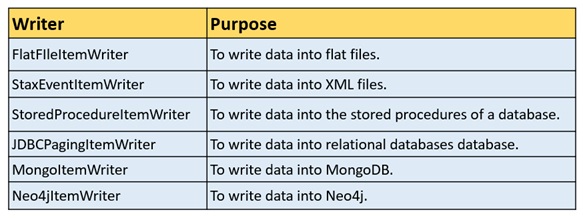
ItemProcessor

ItemProcessor in Spring Batch plays a crucial role in processing data within the batch workflow. It functions by either returning null for invalid items or processing valid items and providing the processed result. The interface ItemProcessor<I,O> is central to this operation.
When a Tasklet class is employed without explicit reader and writer components, it serves as a processor in the Spring Batch. This specialized class focuses on processing a single task.
Custom item processors can be defined by implementing the ItemProcessor interface from the org.springframework.batch.itempackage. This class receives an object, processes the data, and returns the processed data as another object. In a batch process, where “n” records or data elements are read, each record undergoes a cycle of reading, processing, and writing to the specified writer. The processing of data relies on the implemented processor.
import org.springframework.batch.core.configuration.annotation.EnableBatchProcessing;
import org.springframework.batch.core.configuration.annotation.JobBuilderFactory;
import org.springframework.batch.core.configuration.annotation.StepBuilderFactory;
import org.springframework.batch.item.ItemReader;
import org.springframework.batch.item.ItemWriter;
import org.springframework.batch.item.file.FlatFileItemReader;
import org.springframework.batch.item.file.LineMapper;
import org.springframework.batch.item.file.mapping.DefaultLineMapper;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.core.io.ClassPathResource;
import java.util.List;
Need to add code…..
In this example:
itemReader is a bean method that creates an instance of FlatFileItemReader, which reads lines from a flat file.
lineMapper is a bean method that configures the line mapping strategy. In this case, each line is considered as a single item.
itemWriter is a bean method that creates an instance of ItemWriter. In this case, it’s a simple System.out::println that prints each item to the console.
Adjust the logic inside the itemWriter bean method based on your specific requirements.
Remember to further configure your Spring Batch job and step using jobBuilderFactory and stepBuilderFactory according to your needs.
Configuring Job:
There are multiple implementations of the Job interface. However, these implementations are abstracted behind either the provided builders (for Java configuration) The following example shows Java configuration:
@Bean
public Job footballJob(JobRepository jobRepository) {
return new JobBuilder("footballJob", jobRepository)
.start(playerLoad())
.next(gameLoad())
.next(playerSummarization())
.build();
}
A Job (and, typically, any Step within it) requires a JobRepository. The configuration of the JobRepository is handled through the Java Configuration.
The preceding example illustrates a Job that consists of three Step instances. The job-related builders can also contain other elements that help with parallelization (Split), declarative flow control (Decision), and externalization of flow definitions (Flow).
Restartability
One key issue when executing a batch job concerns the behavior of a Job when it is restarted. The launching of a Job is considered to be a “restart” if a JobExecution already exists for the particular JobInstance. Ideally, all jobs should be able to start up where they left off, but there are scenarios where this is not possible. In this scenario, it is entirely up to the developer to ensure that a new JobInstance is created. However, Spring Batch does provide some help. If a Job should never be restarted but should always be run as part of a new JobInstance, you can set the restartable property to false.
The following example shows how to set the restartable field to false in Java:
@Bean
public Job footballJob(JobRepository jobRepository) {
return new JobBuilder("footballJob", jobRepository)
.preventRestart()
...
.build();
}
To phrase it another way, setting restartable to false means “this Job does not support being started again”. Restarting a Job that is not restartable causes a JobRestartException to be thrown. The following Junit code causes the exception to be thrown:
Job job = new SimpleJob();
job.setRestartable(false);
JobParameters jobParameters = new JobParameters();
JobExecution firstExecution = jobRepository.createJobExecution(job, jobParameters);
jobRepository.saveOrUpdate(firstExecution);
try {
jobRepository.createJobExecution(job, jobParameters);
fail();
}
catch (JobRestartException e) {
// expected
}
The first attempt to create a JobExecution for a non-restartable job causes no issues. However, the second attempt throws a JobRestartException.
Intercepting Job Execution
During the course of the execution of a Job, it may be useful to be notified of various events in its lifecycle so that custom code can be run. SimpleJob allows for this by calling a JobListener at the appropriate time:
public interface JobExecutionListener {
void beforeJob(JobExecution jobExecution);
void afterJob(JobExecution jobExecution);
}
You can add JobListeners to a SimpleJob by setting listeners on the job.
The following example shows how to add a listener method to a Java job definition:
@Bean
public Job footballJob(JobRepository jobRepository) {
return new JobBuilder("footballJob", jobRepository)
.listener(sampleListener())
...
.build();
}
Note that the afterJob method is called regardless of the success or failure of the Job. If you need to determine success or failure, you can get that information from the JobExecution:
public void afterJob(JobExecution jobExecution){
if (jobExecution.getStatus() == BatchStatus.COMPLETED ) {
//job success
} else if (jobExecution.getStatus() == BatchStatus.FAILED) {
//job failure
}
}
The annotations corresponding to this interface are:@BeforeJob and @AfterJob
Configuring JobRepository:
As described earlier, the JobRepository is used for basic CRUD operations of the various persisted domain objects within Spring Batch, such as JobExecution and StepExecution. It is required by many of the major framework features, such as the JobLauncher, Job, and Step.
When using @EnableBatchProcessing, a JobRepository is provided for you. This section describes how to customize it. Configuration options of the job repository can be specified through the attributes of the @EnableBatchProcessing annotation, as shown in the following example:
@Configuration
@EnableBatchProcessing(dataSourceRef = "batchDataSource",
transactionManagerRef = "batchTransactionManager",
tablePrefix = "BATCH_",
maxVarCharLength = 1000,
isolationLevelForCreate = "SERIALIZABLE")
public class MyJobConfiguration {
// job definition
}
None of the configuration options listed here are required. If they are not set, the defaults shown earlier are used. The max varchar length defaults to 2500, which is the length of the long VARCHAR columns in the sample schema scripts.
Transaction Configuration for the JobRepository
If the namespace or the provided FactoryBean is used, transactional advice is automatically created around the repository. This is to ensure that the batch metadata, including state that is necessary for restarts after a failure, is persisted correctly. The behavior of the framework is not well defined if the repository methods are not transactional. The isolation level in the create* method attributes is specified separately to ensure that, when jobs are launched, if two processes try to launch the same job at the same time, only one succeeds. The default isolation level for that method is SERIALIZABLE, which is quite aggressive. READ_COMMITTED usually works equally well. READ_UNCOMMITTED is fine if two processes are not likely to collide in this way. However, since a call to the create* method is quite short, it is unlikely that SERIALIZED causes problems, as long as the database platform supports it. However, you can override this setting.
The following example shows how to override the isolation level in Java:
@Configuration
@EnableBatchProcessing(isolationLevelForCreate = "ISOLATION_REPEATABLE_READ")
public class MyJobConfiguration {
// job definition
}
If the namespace is not used, you must also configure the transactional behavior of the repository by using AOP.
The following example shows how to configure the transactional behavior of the repository in Java:
@Bean
public TransactionProxyFactoryBean baseProxy() {
TransactionProxyFactoryBean transactionProxyFactoryBean = new TransactionProxyFactoryBean();
Properties transactionAttributes = new Properties();
transactionAttributes.setProperty("*", "PROPAGATION_REQUIRED");
transactionProxyFactoryBean.setTransactionAttributes(transactionAttributes);
transactionProxyFactoryBean.setTarget(jobRepository());
transactionProxyFactoryBean.setTransactionManager(transactionManager());
return transactionProxyFactoryBean;
}
Changing the Table Prefix
Another modifiable property of the JobRepository is the table prefix of the meta-data tables. By default, they are all prefaced with BATCH_. BATCH_JOB_EXECUTION and BATCH_STEP_EXECUTION are two examples. However, there are potential reasons to modify this prefix. If the schema names need to be prepended to the table names or if more than one set of metadata tables is needed within the same schema, the table prefix needs to be changed.
The following example shows how to change the table prefix in Java:
@Configuration
@EnableBatchProcessing(tablePrefix = "SYSTEM.TEST_")
public class MyJobConfiguration {
// job definition
}
Given the preceding changes, every query to the metadata tables is prefixed with SYSTEM.TEST_. BATCH_JOB_EXECUTION is referred to as SYSTEM.TEST_JOB_EXECUTION.
Only the table prefix is configurable. The table and column names are not.
Non-standard Database Types in a Repository.
If you use a database platform that is not in the list of supported platforms, you may be able to use one of the supported types, if the SQL variant is close enough. To do this, you can use the raw JobRepositoryFactoryBean instead of the namespace shortcut and use it to set the database type to the closest match.
The following example shows how to use JobRepositoryFactoryBean to set the database type to the closest match in Java:
@Bean
public JobRepository jobRepository() throws Exception {
JobRepositoryFactoryBean factory = new JobRepositoryFactoryBean();
factory.setDataSource(dataSource);
factory.setDatabaseType("db2");
factory.setTransactionManager(transactionManager);
return factory.getObject();
}
If the database type is not specified, the JobRepositoryFactoryBean tries to auto-detect the database type from the DataSource. The major differences between platforms are mainly accounted for by the strategy for incrementing primary keys, so it is often necessary to override the incrementerFactory as well (by using one of the standard implementations from the Spring Framework).
If even that does not work or if you are not using an RDBMS, the only option may be to implement the various Dao interfaces that the SimpleJobRepository depends on and wire one up manually in the normal Spring way.
JobLauncher Configuration:
When you use @EnableBatchProcessing, a JobRegistry is provided for you. This section describes how to configure your own.
The most basic implementation of the JobLauncher interface is the TaskExecutorJobLauncher. Its only required dependency is a JobRepository (needed to obtain an execution).
The following example shows a TaskExecutorJobLauncher in Java:
@Bean
public JobLauncher jobLauncher() throws Exception {
TaskExecutorJobLauncher jobLauncher = new TaskExecutorJobLauncher();
jobLauncher.setJobRepository(jobRepository);
jobLauncher.afterPropertiesSet();
return jobLauncher;
}
Once a JobExecution is obtained, it is passed to the execute method of Job, ultimately returning the JobExecution to the caller.
The following Java example configures a TaskExecutorJobLauncher to return immediately:
@Bean
public JobLauncher jobLauncher() {
TaskExecutorJobLauncher jobLauncher = new TaskExecutorJobLauncher();
jobLauncher.setJobRepository(jobRepository());
jobLauncher.setTaskExecutor(new SimpleAsyncTaskExecutor());
jobLauncher.afterPropertiesSet();
return jobLauncher;
}
You can use any implementation of the spring TaskExecutor interface to control how jobs are asynchronously executed.
Running a Job
At a minimum, launching a batch job requires two things: the Job to be launched and a JobLauncher. Both can be contained within the same context or different contexts. For example, if you launch jobs from the command line, a new JVM is instantiated for each Job. Thus, every job has its own JobLauncher. However, if you run from within a web container that is within the scope of an HttpRequest, there is usually one JobLauncher (configured for asynchronous job launching) that multiple requests invoke to launch their jobs.
Running Jobs from the Command Line
If you want to run your jobs from an enterprise scheduler, the command line is the primary interface. This is because most schedulers (with the exception of Quartz, unless using NativeJob) work directly with operating system processes, primarily kicked off with shell scripts. There are many ways to launch a Java process besides a shell script, such as Perl, Ruby, or even build tools, such as Ant or Maven. However, because most people are familiar with shell scripts, this example focuses on them.
The CommandLineJobRunner
Because the script launching the job must kick off a Java Virtual Machine, there needs to be a class with a main method to act as the primary entry point. Spring Batch provides an implementation that serves this purpose: CommandLineJobRunner. Note that this is just one way to bootstrap your application. There are many ways to launch a Java process, and this class should in no way be viewed as definitive. The CommandLineJobRunner performs four tasks:
Load the appropriate ApplicationContext.
Parse command line arguments into JobParameters.
Locate the appropriate job based on arguments.
Use the JobLauncher provided in the application context to launch the job.
You can override this behavior by using a custom JobParametersConverter
In most cases, you would want to use a manifest to declare your main class in a jar. However, for simplicity, the class was used directly. This example uses the EndOfDay example from the The Domain Language of Batch. The first argument is io.spring.EndOfDayJobConfiguration, which is the fully qualified class name to the configuration class that contains the Job. The second argument, endOfDay, represents the job name. The final argument, schedule.date=2007-05-05,java.time.LocalDate, is converted into a JobParameter object of type java.time.LocalDate.
The following example shows a sample configuration for endOfDay in Java:
@Configuration
@EnableBatchProcessing
public class EndOfDayJobConfiguration {
@Bean
public Job endOfDay(JobRepository jobRepository, Step step1) {
return new JobBuilder("endOfDay", jobRepository)
.start(step1)
.build();
}
@Bean
public Step step1(JobRepository jobRepository, PlatformTransactionManager transactionManager) {
return new StepBuilder("step1", jobRepository)
.tasklet((contribution, chunkContext) -> null, transactionManager)
.build();
}
}
The preceding example is overly simplistic, since there are many more requirements to a run a batch job in Spring Batch in general, but it serves to show the two main requirements of the CommandLineJobRunner: Job and JobLauncher.
Exit Codes
When launching a batch job from the command-line, an enterprise scheduler is often used. Most schedulers are fairly dumb and work only at the process level. This means that they only know about some operating system process (such as a shell script that they invoke). In this scenario, the only way to communicate back to the scheduler about the success or failure of a job is through return codes. A return code is a number that is returned to a scheduler by the process to indicate the result of the run. In the simplest case, 0 is success and 1 is failure. However, there may be more complex scenarios, such as “If job A returns 4, kick off job B, and, if it returns 5, kick off job C.” This type of behavior is configured at the scheduler level, but it is important that a processing framework such as Spring Batch provide a way to return a numeric representation of the exit code for a particular batch job. In Spring Batch, this is encapsulated within an ExitStatus, which is covered in more detail in Chapter 5. For the purposes of discussing exit codes, the only important thing to know is that an ExitStatus has an exit code property that is set by the framework (or the developer) and is returned as part of the JobExecution returned from the JobLauncher. The CommandLineJobRunner converts this string value to a number by using the ExitCodeMapper interface:
public interface ExitCodeMapper {
public int intValue(String exitCode);
}
The essential contract of an ExitCodeMapper is that, given a string exit code, a number representation will be returned. The default implementation used by the job runner is the SimpleJvmExitCodeMapper that returns 0 for completion, 1 for generic errors, and 2 for any job runner errors such as not being able to find a Job in the provided context. If anything more complex than the three values above is needed, a custom implementation of the ExitCodeMapper interface must be supplied. Because the CommandLineJobRunner is the class that creates an ApplicationContext and, thus, cannot be ‘wired together’, any values that need to be overwritten must be autowired. This means that if an implementation of ExitCodeMapper is found within the BeanFactory, it is injected into the runner after the context is created. All that needs to be done to provide your own ExitCodeMapper is to declare the implementation as a root level bean and ensure that it is part of the ApplicationContext that is loaded by the runner.
Running Jobs from within a Web Container
Historically, offline processing (such as batch jobs) has been launched from the command-line, as described earlier. However, there are many cases where launching from an HttpRequest is a better option. Many such use cases include reporting, ad-hoc job running, and web application support. Because a batch job (by definition) is long running, the most important concern is to launch the job asynchronously
Async Job Launcher Sequence from web container
The controller in this case is a Spring MVC controller. See the Spring Framework Reference Guide for more about Spring MVC. The controller launches a Job by using a JobLauncher that has been configured to launch asynchronously, which immediately returns a JobExecution. The Job is likely still running. However, this nonblocking behavior lets the controller return immediately, which is required when handling an HttpRequest. The following listing shows an example
@Controller
public class JobLauncherController {
@Autowired
JobLauncher jobLauncher;
@Autowired
Job job;
@RequestMapping("/jobLauncher.html")
public void handle() throws Exception{
jobLauncher.run(job, new JobParameters());
}
}
Batch Processing Guidelines
Dual Architecture Consideration:
Principle: Batch and online architectures impact each other.
Guideline: Design with common building blocks for both architectures.
Simplicity and Logical Structure:
Principle: Simplify batch applications, avoiding complex structures.
Guideline: Keep logical structures straightforward for clarity.
Proximity of Data Processing:
Principle: Keep data processing and storage close.
Guideline: Execute operations where data resides.
Efficient Resource Utilization:
Principle: Minimize system resource usage, especially I/O.
Guideline: Perform operations in internal memory to reduce I/O.
Optimizing Application I/O:
Principle: Avoid unnecessary physical I/O.
Common Flaws: Redundant data reading for transactions.
Unneeded table or index scans. Missing key values in WHERE clauses.
Single Pass Processing:
Principle: Avoid redundant actions in a batch run.
Guideline: Increment stored totals during initial data processing.
Memory Allocation Strategy:
Principle: Allocate sufficient memory at the start.
Guideline: Prevent time-consuming reallocation during processing.
Data Integrity Assurance:
Principle: Assume the worst for data integrity.
Guideline: Implement checks and validations for robustness.
Internal Validation Checksums:
Principle: Use checksums for internal validation.
Example: Include trailer records in flat files for total and key field aggregates.
Stress Testing Preparation:
Principle: Plan and execute stress tests early.
Guideline: Simulate production scenarios with realistic data volumes.
Comprehensive Backup Strategy:
Principle: Prioritize backups in large batch systems.
Guideline: Regularly test and document file backup procedures. Simple Batch Processing Strategies.
Batch Processing Strategy
Conversion Applications:
Purpose: Convert external system files to a standard format.
Example: Translation utility modules.
Validation Applications:
Purpose: Ensure input/output records are correct.
Checks: Headers/trailers, checksums, record-level cross-checks.
Extract Applications:
Purpose: Read records, apply rules, write to output.
Operation: Selects records based on predefined rules.
Extract/Update Applications:
Purpose: Read and update records in a database.
DrivenBy: Data found in each input record.
Processing and Updating Applications:
Purpose: Process input transactions, potentially update database.
Involves: Reading database, updating, creating output.
Output/Format Applications:
Purpose: Restructure data to a standard format.
Use Case: Output for printing or transmission.
Additional Utility Steps:
Sort: Re-sequence records based on sort key. Split: Write records to multiple output files.
Merge: Combine records from multiple files.
Batch Application Sources:
Categories
Database-driven.
File-driven.
Message-driven.
Processing Strategies
Factors: Volume, concurrency, batch windows.
Options:
Normal processing.
Concurrent batch/online.
Parallel processing.
Partitioning.
Combinations of the above.
Database Locking Strategies:
Considerations: Commit points, locking service.
Types: Normal database locks, custom locking service.
Parallel Processing:
Implementation: Multiple jobs concurrently.
Challenges: Load balancing, resource availability.
Partitioning:
Purpose: Run multiple instances of large batch applications.Considerations: Input file split, database table partitioning.
Approaches: Fixed breakup, key column, views, indicators, file extraction, hashing.
Database and Application Design:
Repository: Central partition table for parameters.
Parameters: Program ID, Partition Number, Key Column Range.
Minimizing Deadlocks: Address contention, realistic stress tests.
ParameterPassing: Transparent to developers, validation checks.
Code Snippet for Spring-Batch-Project-CSV-to-DB-processor
Project Structure:

Maven configurationFile(pom.xml):



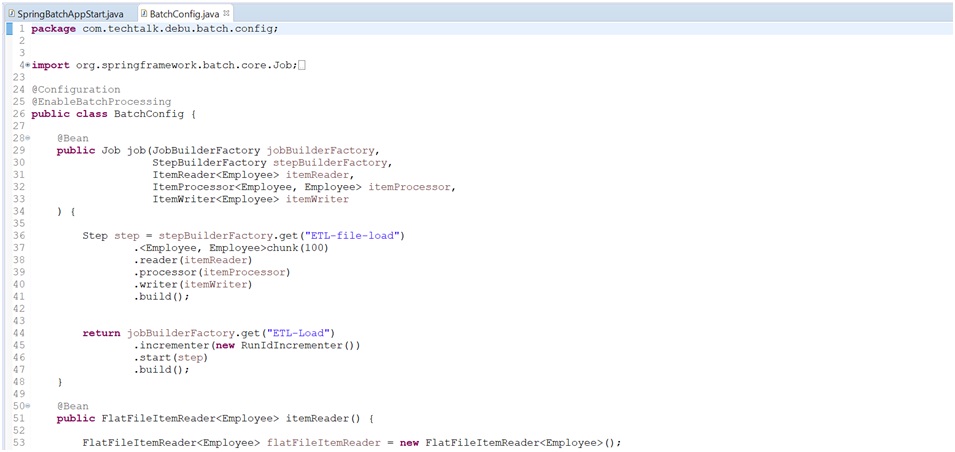
Batch Configuration& Item Reader Class: (BatchConfig.java)

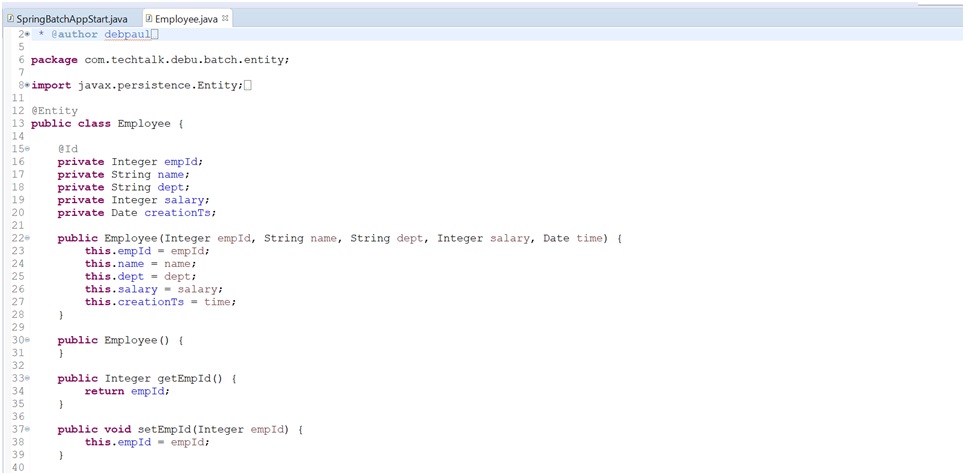
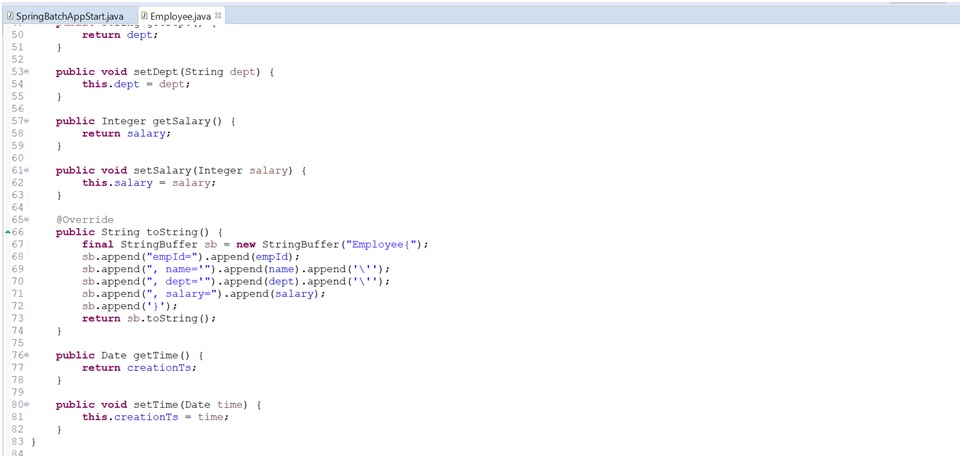
Entity Class: (Employee.java)
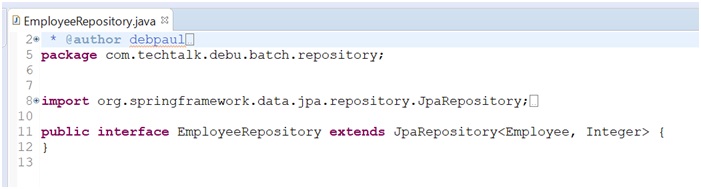
Repository configuration: (EmployeeRepository.java)
Item Processor: (CSVItemProcessor.java)

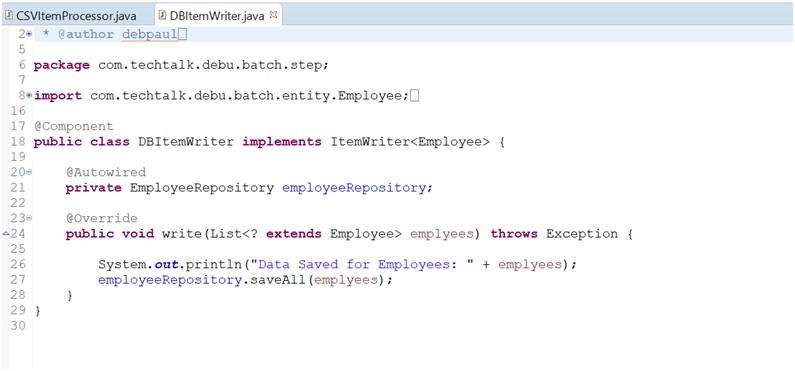
Item Writer:(DBItemWriter.Java)
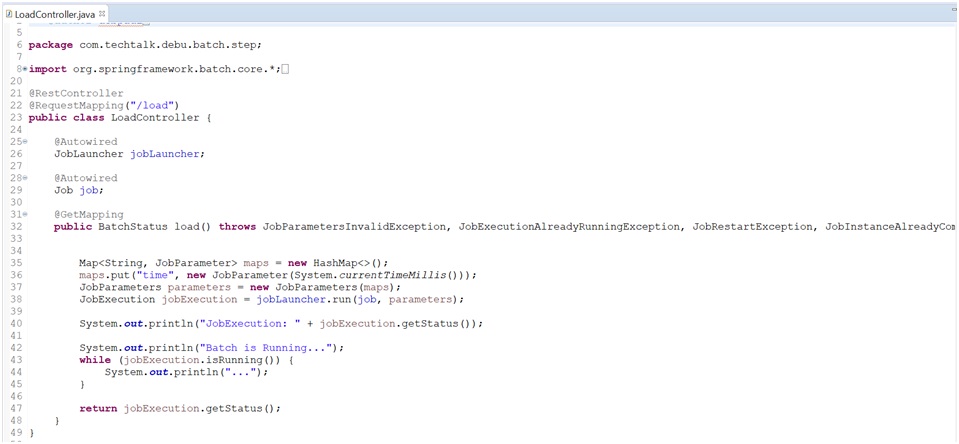
Rest API Controller Class: (LoadController.Java)
Properties File configuration: (application.properties)

Input CSV File:(employees.csv)

Required Software (Environment setup)
JAVA 8
Maven 3.3+
Any IDE Eclipse or IntelliJ
Please note: Mention the Spring Batch Library Dependency in your build tool. (Below example for Maven and Gradle Dependency )

Steps
Download the zip file –

extract the zip file

Import as Maven project in IDE ( or Build in command line : mvn clean install )
URL and DB Details
H2 DB URL: http://localhost:8096/h2-console (any browser you can use) Keep all the information as it is. Only change the DB URL: jdbc:h2:mem:mydb Connect the Database ( Check Employee Table )
Please Note : Once your Application will be up then you can see the DB in the Browser
Running Spring Batch Rest URL: http://localhost:8096/load (Method: GET)
Resources
YouTube video for Detail Explanation of Spring Batch session with example:
More details refer the official documents:
: https://docs.spring.io/spring-batch/reference/
Feedback:
We value your input! Feel free to share your feedback, comments, or suggestions with us. We appreciate hearing from you!
at support@hackeralgo.com.
Acknowledgements:
We extend our heartfelt gratitude to everyone who took the time to review this course and provided valuable insights. Your contributions have been instrumental in enhancing the content, and we are committed to continuous improvement. If you come across any errors or have suggestions, please don’t hesitate to reach out. A special thank you to the following individuals for their noteworthy contributions to this course.